
目錄
在資料分析當中,異常檢測(Anomaly Detection)(或是稱作”異常值檢測(Outlier Detection)”)用來辨識在資料集內非常稀少的項目、事件或者觀測到屬於別種類型資料集的資料等等,那麼最主要的一個問題就是,什麼叫做異常(anomaly)?非常直觀去想就是
異常就是”正常(norm)的變化型態”
所以像是異常值(outliers), 例外情形(exceptions)等等出現在資料集內的值,在現實情境當中這類型的資料可以視作非常重要(significant,或是critical)
其中有兩點是異常檢測特別在意的事情:
- 任務:異常檢測的任務是要從資料點中識別出異常值,可想而知的是資料集內的正常值數量絕對多於異常值,要如何精確的找出異常值是一項挑戰

- 結果輸出:存在兩種輸出的結果
- Binary結果:只會產出yes/no其中一種tag給資料
- Scoring結果:大部分的情況下更常使用這種輸出方法,產出實際的分數或者rank來標示一段範圍來判斷資料是否異常
真實應用情境
- 網路安全: 網路攻擊偵測, 惡意軟體行為辨識, 惡意app或者URL釣魚形式辨認, 生物特徵偽造辨識
- 社群網路與網頁安全: 假帳號或社交工程帳號辨識, 假資訊/惡意資訊等檢測
- 影片監視: 犯罪行為偵測, 交通事故偵測, 激烈行為辨識等等
- 經融: 信用卡/保險紀錄詐騙, 市場操作辨識, 洗錢偵測等等
- 醫療保健: 細胞病變偵測, 腫瘤偵測, IOT/ICU監控事件偵測等等
- 工廠檢測: 缺陷檢查, 微裂痕檢測等等
可以預想異常檢測在現實世界當中擁有許多的實際應用,但隨之而來的是挑戰也成比例的難
異常檢測方法
先簡略介紹一下異常檢測可以透過哪些方法,後續的文章會再更加深入的探討
Time-Series Data
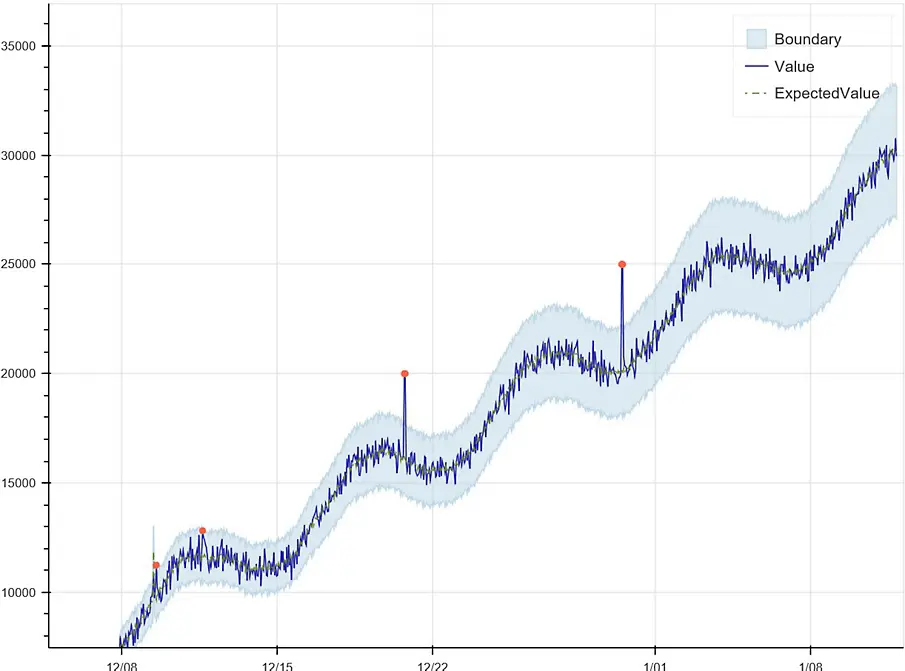
上圖可以看到透過資料時間序列組成了一條界線,在這條界線當中就屬於時間序列中正常的行為,而那些超出界線的紅點就可以視為屬於異常的資料
Multivariate Datas
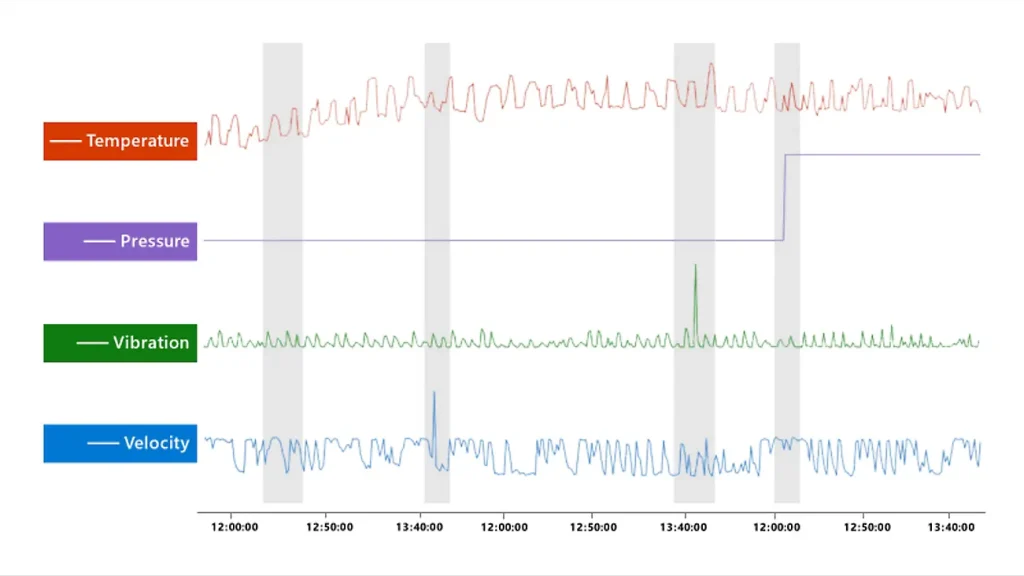
另外一種想法就是取得多種資料訊號,並且這些資料都需要是相關的,透過瞬間變化來判斷是否有哪一段時間的行為屬於異常的,又或者可以透過蒐集到的資料來進行預測
主要的挑戰
不同於傳統的機器學習,異常檢測要面臨的是更多的難題如下:
- 找到有效的特徵能夠從正常的資料集內分辨出異常值
- 將正常的資料與異常的行為邊界給訂定出來總是不太精確
- 不同的檢測情境所需要的異常值都差個十萬八千里,沒有統一的SOP
- 標記好的資料對於訓練或驗證的作用有限,用來訓練的異常資料太少
- 資料集內可能會存在高雜訊的資料,使得異常的資料特徵被忽視
- 正常的行為資料會持續的變化,使得異常值也需要常常重取
圖片、影像異常辨識
很常見的情境當然就屬從一系列的圖片按照時間序監控錄下來辨識anomalies(或是outliers),或是檢測圖片中異常的區域,圖片蒐集的越多,越能夠紀錄正常的特徵行為將其用來訓練,從而找出異常的樣本,所以Deep Learning的方法在異常檢測是非常合理的選擇
異常檢測問題類型
Supervised Anomaly Detection
繼承於傳統的supervised特性,用來檢測anomalies絕對是最精確的方法,但受限於異常檢測中abnormal的資料實在太少,所以常常都是傾斜(skewed或是imbalanced) classification
Semi-supervised Anomaly Detection
相似於傳統機器學習的方法,只標記少部分的資料,結合了supervised以及unsupervised特性
Unsupervised Anomaly Detection
依照情境的不同有時也可能選用這種方法,像是核電廠、導彈發射系統等即時性的情境,若要為了訓練資料讓其出現錯誤來蒐集異常行為可能會付出高昂的代價以及一定程度的危險性,故這種情境下還是選擇unsupervised的方法較為保險,並且這一類的異常跟正常行為相比數量實在太為稀少了
再來介紹一下不同型態的anomalies
異常型態
Point Anomalies
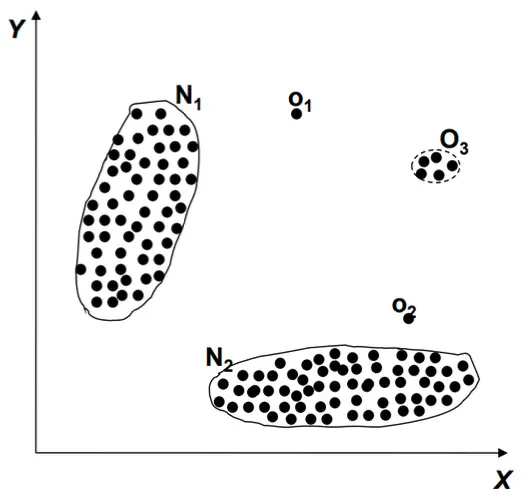
上圖將資料分類成點型態,透過不同的分類方法像是clustering等,單獨的instances \(O_{1}\)或是\(O_{2}\)就可以發現是異常的,當然還需要取決於資料X的判斷
Contextual Anomalies
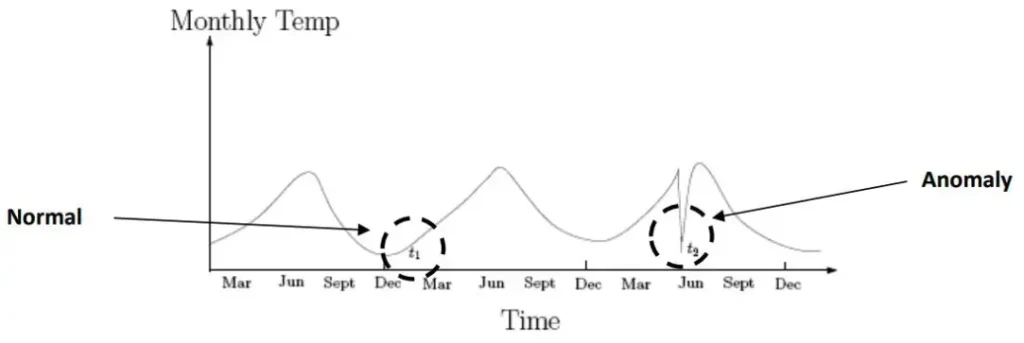
第二個型態叫做contextual anomalies,根據情境的不同找出異常值,上圖是月份的氣溫時序圖,可以看到\(t_{1}\)在十二月到三月之間氣溫很平滑的變化,但在\(t_{2}\)的時候看到六月有一個急遽的氣溫下降,這在過去的經驗來看六月應該漸漸變熱,所以可以判斷\(t_{2}\)屬於一個異常值,這類型的資料型態通常需要情境的概念,同時要根據不同情境條件下來判斷是不是anomalies
Collective Anomalies
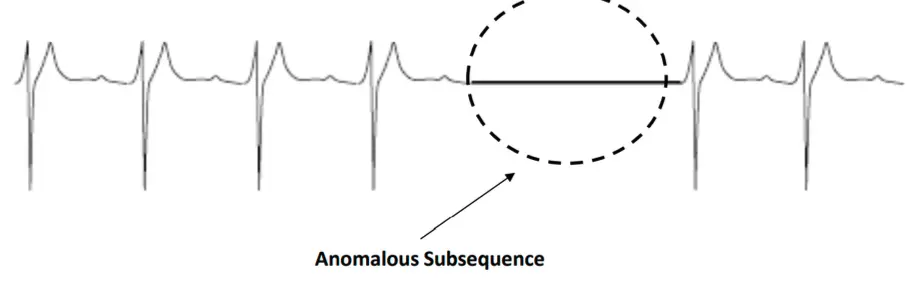
第三種屬於集體式的異常資料,需要先蒐集大量相關的anomalies instances,像是時間序列資料、空間資料以及圖像資料等等,單一的異常instances出現在collective anomalies之間不代表該項instances就屬於異常,因為我們在進行分群的時候本來就會讓異常值聚集在某個point上,但也有可能是正常資料中的離群值不斷趨近異常值的群點中心
Outliers
所以離群值在異常檢測中也必須要探討,按照傳統的深度學習方法,這些定量的資料經常使用統計上的分佈來進行分析,在異常檢測當中也是照常這樣做,一些常見的分佈也一樣好用
- Uniform Distribution
- Normal Distribution
- 其他Unimodal Distributions
- Multimodal Distributions
同樣的在異常檢測當中也存在one-dimensional以及multi-dimensional的不同分佈形態

